دوره آموزشی

دوبله زبان فارسی
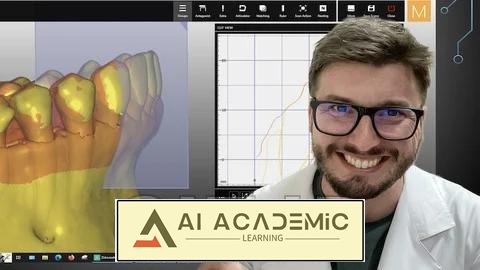
تشخیص گفتار با پایتون

✅ سرفصل و جزئیات آموزش
در این دوره، شما تشخیص گفتار با پایتون را از اصول اولیه تا کاربردهای پیشرفته هوش مصنوعی فرا خواهید گرفت.
آنچه یاد خواهید گرفت:
- اصول اولیه تشخیص گفتار
- پایتون برای تشخیص گفتار
- تکنیک های پردازش صدا
- الگوریتم های پیشرفته هوش مصنوعی
- ساخت اپلیکیشن های گفتار به متن
- کاربردهای عملی هوش مصنوعی
- پیاده سازی متن به گفتار
پیش نیازهای دوره
- مهارت های اولیه برنامه نویسی پایتون
- درک پایه از یادگیری ماشین
توضیحات دوره
چه چیزی خواهید آموخت؟
- مبانی تشخیص گفتار: کشف کنید که چگونه صدا به داده دیجیتال تبدیل، پردازش می شود و به متن تبدیل می گردد و پایه ای قوی و نظری را از مدلسازی آکوستیک تا الگوریتم های پیشرفته بسازید.
- پروژههای عملی پایتون: استفاده از کتابخانه های قدرتمند پایتون برای پردازش، مصورسازی و ترنسکرایب کردن فایل های صوتی و یادگیری رویکردهای آنلاین و آفلاین برای توسعه اپلیکیشن های گفتار به متن
- تکنیک های پیشرفته: بررسی عمیق مدل های مارکوف پنهان، شبکه های عصبی و ترانسفورماتورها، درک مکانیزم های پشت سیستم های تشخیص گفتار مدرن و کشف نحوه استفاده آنها در کاربردهای دنیای واقعی
- کاربردهای عملی: تسلط به مهارت های لازم برای ساخت دستیارهایی با فرمان صوتی، بهبود دسترسی و توسعه راه حل هایی برای تصمیم گیری داده محور
این دوره برای چه کسانی مناسب است؟
- مهندسان هوش مصنوعی
- توسعه دهندگان هوش مصنوعی
- دانشمندان داده
- علاقه مندان به فناوری
تشخیص گفتار با پایتون
-
به دنیای تشخیص گفتار خوش آمدید 04:50
-
رویکرد دوره 04:19
-
چگونه همه چیز آغاز شد: فرمانت ها، هارمونیک ها و واج ها 03:20
-
توسعه و تکامل 04:06
-
چگونه انسان ها گفتار را تشخیص می دهند؟ 03:16
-
اصول اولیه صدا و امواج صوتی 03:28
-
خواص امواج صوتی 05:48
-
مفاهیم کلیدی: سمپل ریت، عمق بیت و نرخ بیت 05:02
-
پردازش سیگنال صوتی برای یادگیری ماشین و هوش مصنوعی 04:45
-
ویژگی های صوتی حوزه زمان 06:53
-
ویژگی های صوتی حوزه فرکانس و حوزه زمان-فرکانس 06:19
-
استخراج ویژگی های حوزه زمان: فریم بندی و محاسبه ویژگی ها 04:43
-
استخراج ویژگی های حوزه فرکانس: تبدیل فوریه 04:27
-
ویژگی های صوتی None
-
مدلسازی آکوستیک و زبانی 03:49
-
مدل های مارکوف پنهان (HMM) و شبکه های عصبی سنتی 06:30
-
مدل های یادگیری عمیق: CNN ،RNN و LSTM 06:36
-
سیستم های پیشرفته تشخیص گفتار: ترانسفورمرها 04:52
-
ساخت یک مدل تشخیص گفتار - قسمت 1 04:26
-
ساخت یک مدل تشخیص گفتار - قسمت 2 04:19
-
انتخاب ابزار مناسب تشخیص گفتار 05:48
-
مکانیزم های تشخیص گفتار None
-
نصب Anaconda 02:24
-
ایجاد یک محیط جدید 02:47
-
نصب بسته ها برای تشخیص گفتار 06:16
-
ایمپورت کردن بسته های مرتبط در Jupyter 03:11
-
فرمت های فایل صوتی برای تشخیص گفتار 07:04
-
ایمپورت کردن فایل های صوتی در Jupyter Notebook 07:47
-
کتابخانه Google Web Speech API :SpeechRecognition 08:32
-
معیارهای ارزیابی: WER و CER 03:11
-
محاسبه WER و CER در پایتون 05:34
-
ترنسکرایب کردن صدا با Google Web Speech API None
-
درک نویز در فایل های صوتی 03:59
-
ایجاد اسپکتروگرام با پایتون 07:22
-
برخورد با نویز پس زمینه 08:50
-
Whisper AI: متن به گفتار مبتنی بر ترانسفورمر 07:36
-
ترنسکرایب کردن چندین فایل صوتی از یک دایرکتوری 05:22
-
ذخیره ترانسکریپت های صوتی در فایل CSV برای تحلیل آسان 05:05
-
معکوس کردن فرآیند: متن به گفتار مبتنی بر هوش مصنوعی 03:24
-
ترنسکرایب کردن صدا با Whisper OpenAI None
-
شیوه ها و کاربردهای مدرن 05:10
-
چالش ها و محدودیت ها 02:36
-
آینده تشخیص گفتار با هوش مصنوعی 03:42
مشخصات آموزش
تشخیص گفتار با پایتون
- تاریخ به روز رسانی: 1404/06/14
- سطح دوره:همه سطوح
- تعداد درس:43
- مدت زمان :03:20:02
- حجم :2.08GB
- زبان:دوبله زبان فارسی
- دوره آموزشی:AI Academy
آموزش های مرتبط
The Great Courses
651,500
130,300 تومان
- زمان: 01:39:55
- تعداد درس: 6
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
1,889,000
377,800 تومان
- زمان: 04:47:39
- تعداد درس: 30
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
1,501,000
300,200 تومان
- زمان: 03:48:11
- تعداد درس: 47
-
سطح دوره:
-
زبان: دوبله فارسی

-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
490,000
98,000 تومان
- زمان: 54:55
- تعداد درس: 18
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
1,797,000
359,400 تومان
- زمان: 04:33:59
- تعداد درس: 86
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
2,659,500
531,900 تومان
- زمان: 06:44:45
- تعداد درس: 35
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
7,300,500
1,460,100 تومان
- زمان: 18:29:24
- تعداد درس: 115
-
سطح دوره:
-
زبان: دوبله فارسی

The Great Courses
2,113,000
422,600 تومان
- زمان: 05:21:41
- تعداد درس: 51
-
سطح دوره:
-
زبان: دوبله فارسی